| Namespace | No namespace | ||
|
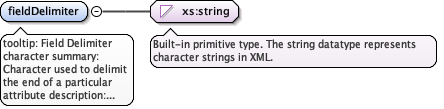
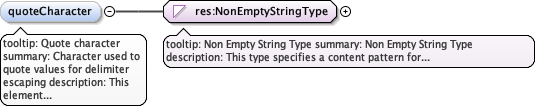
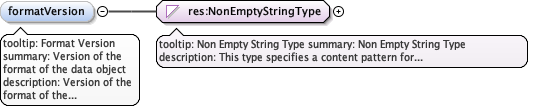
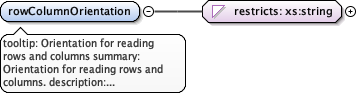
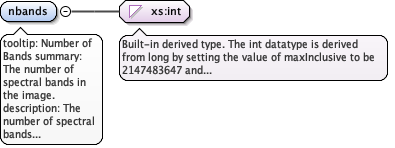
Annotations
|
|
||
|
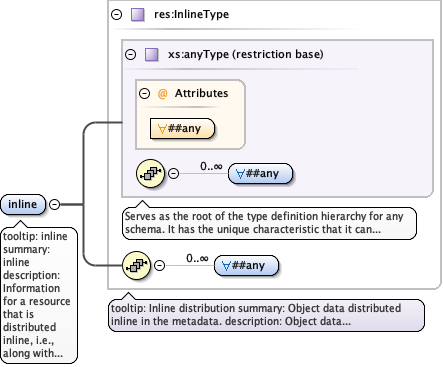
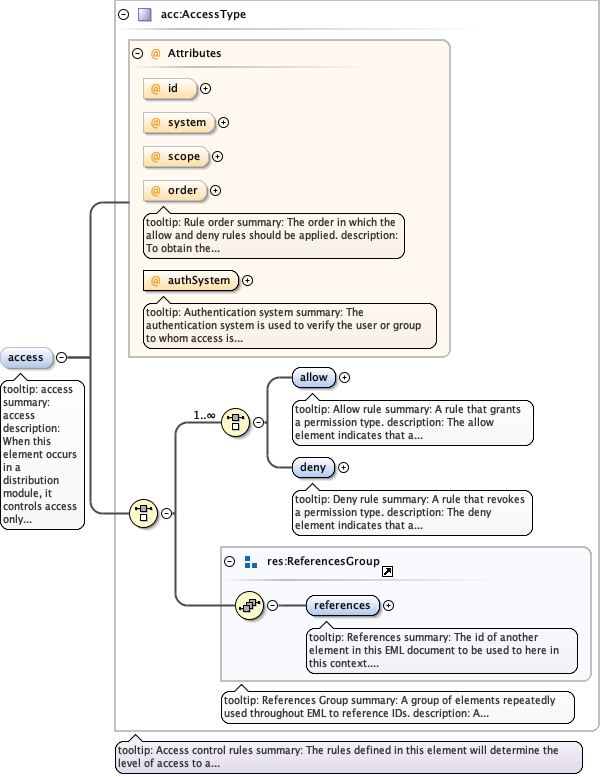
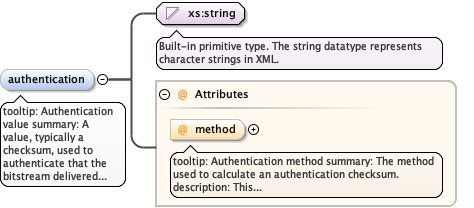
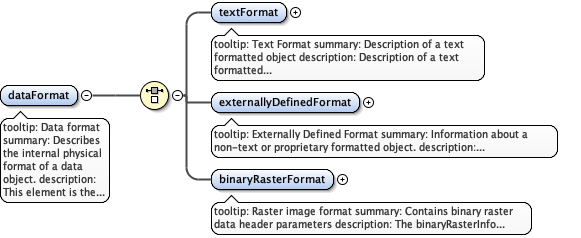
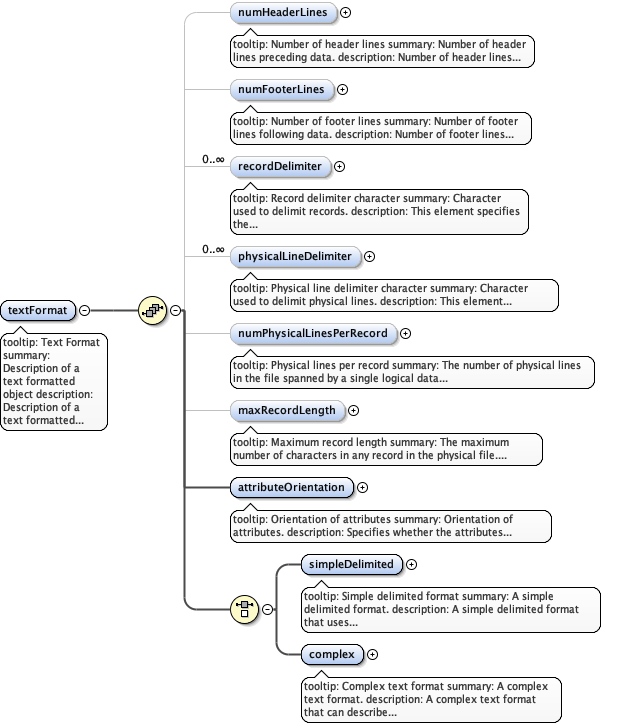
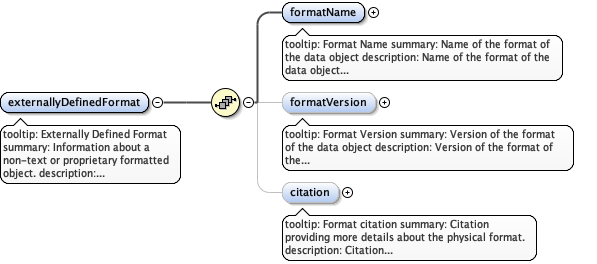
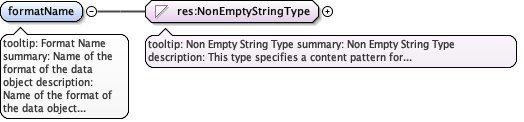
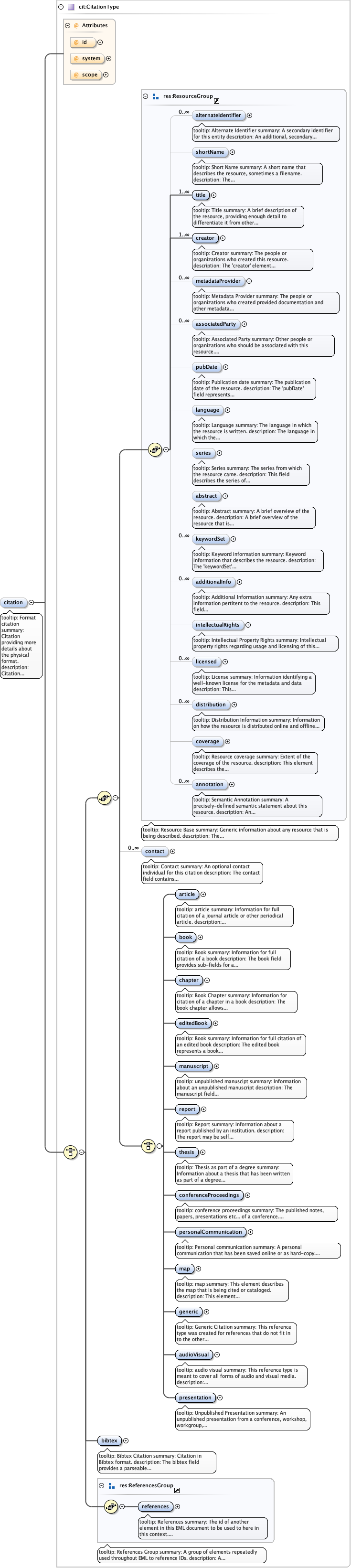
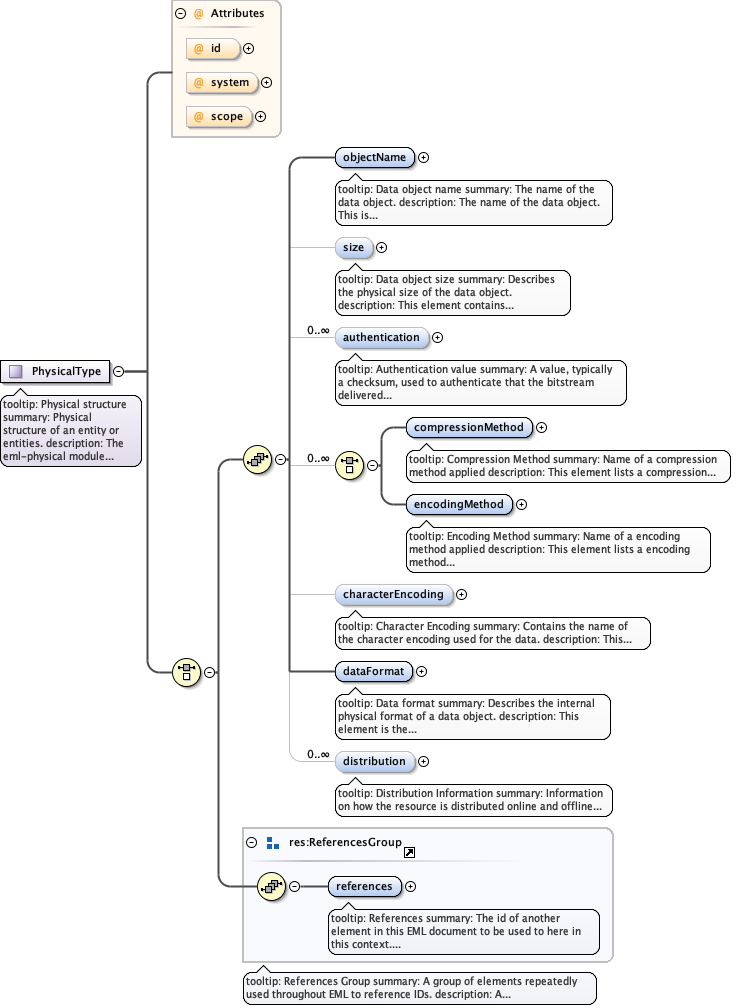
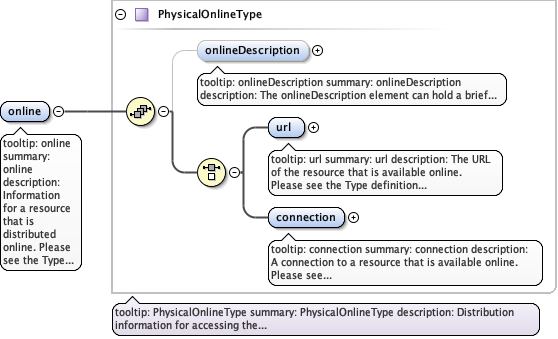
Diagram
|
 |
||
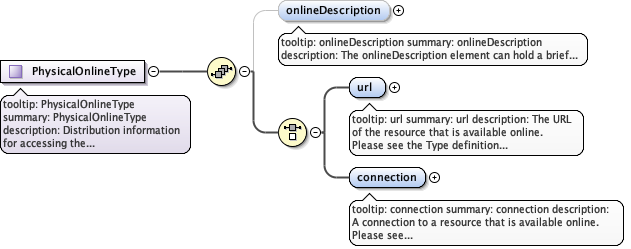
| Type | PhysicalOnlineType | ||
|
Properties
|
|
||
| Model | |||
| Children | connection, onlineDescription, url | ||
|
Instance
|
|