Implementation Priority¶
| Submitted by: | DataONE Core Cyberinfrastructure Team / Virtual Data Center Technical Working Group |
|---|---|
| Revisions: |
|
Introduction¶
The DataONE Core Cyberinfrastructure Team / Virtual Data Center Technical Working Group (CCIT/VDC TWG, hereafter CCIT) was charged with developing a prioritization of the approximately three dozen use cases developed to date. The prioritization was to be shared with the DataONE Leadership Team in order to come to agreement for the development priorities for years 1 through 5. This agreement was considered an important deliverable for the DataONE kickoff meeting in October 2009.
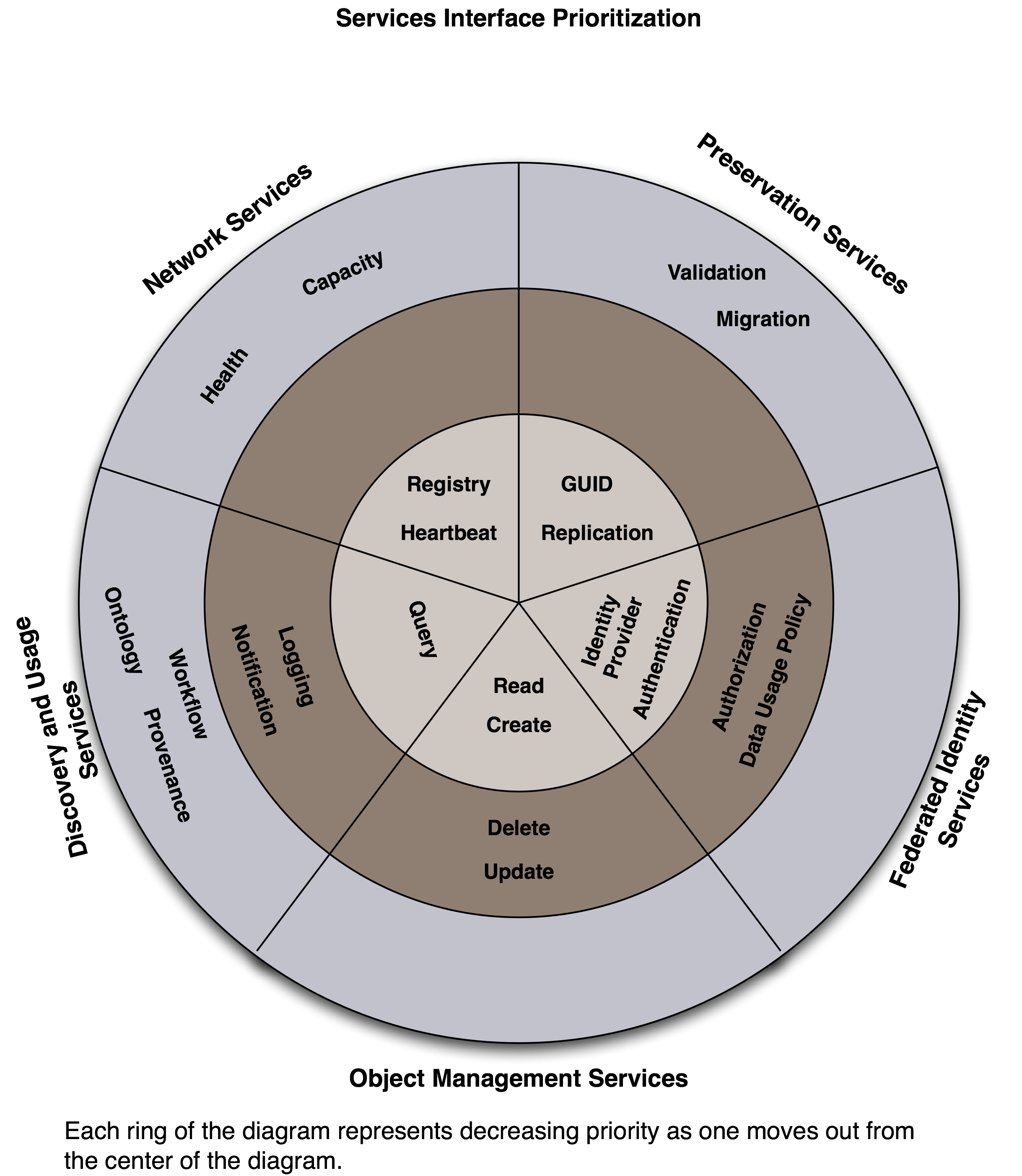
The CCIT reviewed existing documents, including the CI Preliminary Task List, the Service Interface Prioritization diagram, the DataONE – VDC June 2009 Technical Working Group Meeting Report, and the DataNetONE Implementation Plan (primarily Objective 4) – see References, below. The use cases are defined in the DataONE Architecture document available at https://mule1.dataone.org/ArchitectureDocs. Goals and milestones expressed in the CI Preliminary Task List were foundational for developing the proposed prioritization (see Table 1).
In some instances, use case implementations in the early years may be partial or limited implementations with work continuing in later years until completion. Examples of use cases that are likely to be improved over time include authentication, logging, search and retrieval, event notifications, etc. Work on other goals and milestones will begin as early as year 1, led by the appropriate working group, with the initial implementation in a subsequent year (e.g., scientific use cases; workflow support; ontology support). Certain goals and milestones (e.g., replication of data and metadata) will be met by evaluating alternatives and selecting a set of existing software applications. Additional details about Member Nodes will be provided in a separate document, forthcoming. This prioritization is mapped optimistically to the 5-year schedule: goals, milestones, and specific use cases that are the best candidates for potential deferral are indicated in the table and discussion below.
The CCIT reviewed the prioritization, distributed it to the Leadership Team, and discussed the prioritization during a videoconference held October 13, 2009. Improvements identified during the videoconference were incorporated into the document, which was then distributed at the DataONE kickoff meeting held October 20-22, 2009.
| Goal / Milestone | V 0.x | V 1.x | V 2.x |
|---|---|---|---|
| Launch 3 Coord. / 3 Member Node network | X | ||
| Initial persistent identifier support | X | ||
| Formalize service APIs | X | ||
| Reference service / client implementations | X | ||
| Authentication: short- then long-term | X | X | |
| Search, retrieval, metadata interoperability | X | X | X |
| DataONE User Interface | X | X | X |
| DataONE Investigator Toolkit | X | X | X |
| Replication of data and metadata | X | X | |
| Heartbeat / health monitor (basic to robust)* | X | X | X |
| Logging (basic to robust)* | X | X | |
| Member Node registry | X | X | |
| Additional Member Nodes | X | X | |
| Data / metadata deposit, update, delete | X | ||
| Identity provider (external or internal) | X | ||
| Authorization | X | ||
| Notification of DataONE events* | X | X | |
| Data usage policy support | X | ||
| Web-based batch data uploads | X | ||
| Launch robust public prototype | X | ||
| Support scientific use cases | X | ||
| Client discovery services | X | ||
| Batch ingest for data / metadata | X | ||
| Stress and load testing | X | ||
| Coordinating Node failover / load balancing* | X | ||
| Data and metadata validation | X | ||
| Data and metadata migration | X | ||
| Workflow support | X | ||
| Ontology support | X | ||
| Provenance support | X | ||
| Support advanced scientific use cases | X | ||
| Capacity monitoring | X | ||
| Hardened infrastructure | X |
Table 1: Goal / milestone summary by implementation version. Goals / milestones with asterisks could be deferred to the following year. X indicates the phase of development planned for implementation of that feature, and when appearing in multiple columns indicates that iterative development of that feature is expected.
Notes¶
Prioritizing system implementation to address the use cases involves several factors including:
- Vision of the project. The system is being designed with some overall goals described by the vision of the project proposal.
- Requirements of the community. The stakeholders that comprise the user and participant community quite likely has some opinion on functionalities of the system that are important to them. If these are not properly addressed, then the resulting system may appear as a failure to them.
- Requirements of the sponsor. The sponsor has laid out goals in the RFP that the project is responding to and also in the final agreement for conducting the work.
- Dependencies between use cases. Implementation of functionality to address some use cases will require implementation of some components not directly specific in a use case.
- Resources available for implementation. Some use cases may be identified as high priority, but would require resources that would prevent implementation of a number of other lower priority features.
Version 0.x Implementation¶
The 0.x series of implementation is anticipated to be essentially prototyping and proof of concept activities where critical infrastructure components and information flows are evaluated for scalability and reliability. It is not anticipated that this series of releases will be generally available as public services (except with the caveats of temporary, unstable, and in development implementation).
Goals and Milestones¶
The goals and milestones for the version 0.x series of DataONE cyberinfrastructure include:
- Launching a network consisting of three Coordinating Nodes and three Member Nodes
- Initial support for PIDs (persistent, unique identifiers)
- Formalize service APIs
- Provide reference service / client implementations
- Authentication using a short-term solution
- Search and retrieval of data from all Member Nodes to demonstrate basic metadata interoperability (initial release)
- DataONE user interface (initial release)
- DataONE Investigator Toolkit (initial release)
- Replication of data and metadata between Coordinating and Member Nodes, bootstrapped using existing repositories
- Heartbeat / health monitoring (initial release)
- Infrastructure (initial release)
- Member Node registry services (initial release)
Use Cases¶
Authentication Using Short-term Solution
Use Case 12 - User Authentication: Person, via client software, authenticates against Identify Provider to establish session token. Many operations in the DataONE system require user authentication to ensure that the user’s identity is known to the system, and that appropriate access controls can be executed based on the identity.
Use Case 14 - System Authentication and Authorization: System Authentication/Authorization - Server authenticates and performs system operations (e.g. replication). This use case represents node-to-node authentication.
Search and Retrieval, Indexing, Read Data and Metadata, Metadata Interoperability
Use Case 1 - CRUD get(): Get object identified by an identifier (authenticated or not, notify subscriber of access). A client has an identifier for some object within the DataONE system and is retrieving the referenced object. The DataONE system must resolve the identifier and return the object bytes after checking that the user has read privileges on the object.
Use Case 02 - List identifiers By Search: Get list of identifiers from metadata search (anonymous and authenticated). A user performs a search against the DataONE system and receives a list of object identifiers that match the search criteria. The list of identifiers is filtered such that only objects for which the user has read permission will be returned. This use case assumes that the search is being performed by submitting a query against a CN.
Replication of Data and Metadata
Use Case 06 - MN Synchronize: Copy metadata record from Member Node to Coordinating Node. As data are created or modified, the metadata associated with those is copied to the to the Coordinating Nodes. The presence of new or changed information on a Member Node (MN) is made known to a Coordinating Node (CN) through the status information in a ping() response. If so indicated, the CN schedules a synchronization operation with the MN, a list of changed object identifiers is retrieved by the CN, and the CN proceeds to retrieve and process each object. If new data packages are present on the MN, then a MN-MN replication process is scheduled.
Use Case 09 - Replicate MN to MN: Replicate data from Member Node to Member Node - (facilitated by Coordinating Node).
Use Case 24 - MNs and CNs Support Transactions: Transactions - CNs and MNs should support transaction sets where operations all complete successfully or get rolled back (e.g., upload both data and metadata records). Implementation of this use case could be deferred to year 2.
Basic Heartbeat / Health Monitoring
Use Case 10 - MN Status Reports: Coordinating Node checks “liveness” of all Member Nodes. Implementation of this use case could be deferred to year 2.
Basic Logging Infrastructure
Use Case 16 - Log CRUD Operations: All CRUD operations on metadata and data are logged at each node. Implementation of this use case could be deferred to year 2.
Use Case 17 - CRUD Logs Aggregated at CNs: All CRUD logs are aggregated at Coordinating Nodes. Implementation of this use case could be deferred to year 2.
Basic Member Node Registry Services
Use Case 03 - Register MN: Register a new Member Node. This use case describes the technical process for addition of a new Member Node (MN) to the DataONE infrastructure. It is assumed that the appropriate social contracts have been formed and the MN is operational, ready to be connected.
Version 1.x Implementation¶
The version 1.x series of DataONE cybrinfrastructure will provide a full public release that will support the basic functionality for long-term archive of content, discovery of content (search and browse), and basic data manipulation and visualization.
Goals and Milestones¶
The version 1.x goals and milestones for DataONE include:
- Deploy additional Member Nodes
- Data and metadata deposit, update, and delete
- Implement an external or internal identity provider
- Implement authorization
- Support notifications based upon DataONE events
- Support negotiated and approved data usage policies
- Web-based interface for batch data uploads
- Search and retrieval of data from all Member Nodes
- DataONE user interface
- DataONE Investigator Toolkit
- Heartbeat / health monitoring
- Logging infrastructure
- Member Node registry services
- Launching a robust public prototype
- Support selected scientific use cases
- Authentication using a long-term solution
- Implement client discovery services
- Batch ingest support
- Conducting stress and load testing
- Implementing Coordination Node failover and load balancing
- Support notifications based upon DataONE events
It is anticipated that additional use cases and milestones will be identified during the previous phases of development and as outputs from the various activities of the DataONE working groups.
Use Cases¶
Data and Metadata Deposit, Update, and Delete
Use Case 04 - CRUD (Create, Update Delete) Metadata: Create, update or delete metadata record on a Member Node. A user is creating a new metadata record on a Member Node (MN). The mechanism by which the user does this is out of scope for the DataONE system, so this use case continues from the point where a new Data Package is present on the MN. The metadata is retrieved by the CN using a pull mechanism (CN requests content from the MN).
Use Case 05 - CRUD (Create, Update Delete) Data: Create/Update/Delete data object in Member Node. May split out the update and delete portions to different use cases at some point in the future.
Use Case 23 - Owner Expunge Content: User can find out where all copies of my data are in the system and can expunge them. Implementation of this use case could be deferred to year 3.
Client Discovery Services
Use Case 33 - Search for Data: Clients should be able to search for data using CN metadata catalogs.
Use Case 34 - CNs Support Other Discovery Mechanisms (e.g. Google): Coordinating Nodes publish metadata in formats for other discovery services like Google/Libraries/GCMD/etc.
Identity Provider
Use Case 15 - Account Management: User Account Management - Create new user account on Identity Provider (also edit, delete).
Authentication Using a Long-Term Solution
Use Case 12 - User Authentication: Person, via client software, authenticates against Identify Provider to establish session token. Many operations in the DataONE system require user authentication to ensure that the user’s identity is known to the system, and that appropriate access controls can be executed based on the identity.
Use Case 14 - System Authentication and Authorization: System Authentication/Authorization - Server authenticates and performs system operations (e.g. replication). This use case represents node-to-node authentication.
Support Authorization
Use Case 13 - User Authorization: ser Authorization - Client requests service (get, put, query, delete, ...) using session token.
Support Data Usage Policies
Use Case 08 - Replication Policy Communication: Communication of replication policy metadata between Member Nodes and Coordinating Nodes. The replication policy of Member Nodes (MN) indicates factors such as the amount of storage space available, bandwidth constraints, the types of data and metadata that can be managed, and perhaps access control restrictions. This information is used by Coordinating Nodes (CN) to balance the distribution of data packages throughout the DataONE system to achieve the goals of data package persistence and accessibility.
Use Case 31 - Manage Access Policies: Manage Access Policies - Client can specify access restrictions for their data and metadata objects. Also supports release time embargoes.
Enhance the Logging Infrastructure
Use Case 16 - Log CRUD Operations: All CRUD operations on metadata and data are logged at each node.
Use Case 17 - CRUD Logs Aggregated at CNs: All CRUD logs are aggregated at Coordinating Nodes.
Use Case 18 - MN Retrieve Aggregated Logs: Member nodes can request aggregated CRUD log for {time period/object id/userid} for all of ‘their’ objects. Implementation of this use case could be deferred to year 3.
Use Case 19 - Retrieve Object Download Summary: General public can request aggregated download usage information by object id. Implementation of this use case could be deferred to year 3.
Use Case 20 - Owner Retrieve Aggregate Logs: Data owners can request aggregated CRUD log for {time period/object id} for all of ‘their’ objects. Implementation of this use case could be deferred to year 3.
Use Case 22 - Link/Citation Report for Owner: User can get report of links/cites my data (also can view this as a referrer log).
Support Notifications Based Upon DataONE Events
Use Case 21 - Owner Subscribe to CRUD Operations: Data owners can subscribe to notification service for CRUD operations for objects they own.
Use Case 28 - Derived Product Original Change Notification: Relationships/Versioning - Derived products should be linked to source objects so that notifications can be made to users of derived products when source products change.
Batch Ingest
Use Case 07 - CN Batch Upload: Batch Operations - Coordinating Node requests metadata /data list from new Member Node and then batch upload (disable indexing for example to improve insert performance).
Coordination Node Failover and Load Balancing
Use Case 29 - CN Load Balancing: Load Balancing - Requests to Coordinating Nodes are load balanced. Implementation of this use case could be deferred to years 4-5.
Version 2.x Implementation¶
The version 2.x series builds upon the core functionality provided in the 1.x releases and generally addresses the more advanced science user requirements such as semantic integration of content and additional services for data extraction, conversion, analysis and visualization.
Goals and Milestones¶
The version 2.x series goals and milestones for DataONE include:
- Deploy additional Member Nodes
- Data and metadata validation
- Data and metadata migration
- Workflow support
- Ontology support
- Provenance support
- Support for general and innovative scientific use cases (subsetting, translation, semantic interoperability, advanced visualization, etc.)
- Capacity monitoring
- Hardening of overall infrastructure into a robust system
- Search and retrieval of data from all Member Nodes
- DataONE user interface
- DataONE Investigator Toolkit
- Heartbeat / health monitoring
- Support notifications based upon DataONE events
It is anticipated that additional use cases and milestones will be identified during the previous phases of development and as outputs from the various activities of the DataONE working groups.
Use Cases¶
Data and Metadata Validation
Use Case 25 - Detect Damaged Content: System should scans for damaged/defaced data and metadata using some validation process.
Use Case 26 - Data Quality Checks: System performs data quality checks on data.
Data and Metadata Migration
Use Case 27 - Metadata Version Migration: CN should support forward migration of metadata documents from one version to another within a standard and to other standards.
Workflow Support
Use Case 11 - CRUD Workflow Objects: Create / update / delete / search workflow objects.
Provenance Support
Use Case 28 - Derived Product Original Change Notification: Relationships/Versioning - Derived products should be linked to source objects so that notifications can be made to users of derived products when source products change.
Use Case 32 - Transfer Object Ownership: User or organization takes over ‘ownership’ of a set of objects (write access for orphaned records).
Complete Heartbeat / Health Monitoring
Use Case 30 - MN Outage Notification: MN can notify CN about pending outages, severity, and duration, and CNs may want to act on that knowledge to maintain seamless operation.
References¶
CI Preliminary Task List, available at https://repository.dataone.org/documents/Meetings/20090210-mat-santa-barbara-mtg/CI_preliminary_tasklist_021809.xls
DataONE Architecture, available at: https://repository.dataone.org/documents/Projects/VDC/docs/service-api/api-documentation/build/html
DataONE – VDC June 2009 Technical Working Group Meeting Report, https://repository.dataone.org/documents/Projects/VDC/docs/20090602_04_ABQ_Meeting/20090604MeetingReport.pdf
Service Interface Prioritization (diagram), available at https://repository.dataone.org/documents/Projects/VDC/docs/service-api/api-diagrams/service-api-layers.png
{kind=link}